
Table of Contents
It’s Not What A Book Says, It’s How It Makes You Feel
“Boring, but a real problem to solve”
Article after winning FutureBook BookTech Company of the year (thanks for the backhanded comment!)
If you buy a TV, you’re interested in the viewing experience, the depth of color, the fluidity of movement across the screen and so forth. You’re probably less interested in the plastic of the case, the quality of the internal cables or circuitboard. Marketers target the former, knowing the decision to buy is often an emotional one. Books typically teach you something or make you feel a certain way. If anything, the emotional connection between a book and a reader is more important compared to most other products.
What is the best source for learning how a book made people feel? Reader reviews. And unlike other products, readers typically write a lot about their reading experiences in reviews. So, at this point I had the right data sourcing, feature engineering and training infrastructure, plus a solid corpus of book data. I leveraged this foundation to pull down tens of millions of book reviews from multiple sites such as Amazon, GoodReads, LibraryThing and more.
My Reader Experience Is My Buying Intent
Using the same data and algorithms to find a keyword universe for a book based on browse nodes, I pivoted from using features derived from the book text, to features derived from book reviews and other book metadata instead. In hindsight, this made a lot of sense since readers express their buying intent in similar language to their reading experience.
This approach also meant I could then generate keywords using only an Amazon ASIN (which is a unique product ID on Amazon). For books that didn’t have enough reviews, I could pull together the reviews of comparable books (more on that later).
Author Checkpoint
Instead of testing with publishers first, this time I launched an author marketing and analysis platform called Author Checkpoint to validate various models with authors. Authors could enter any Amazon book and generate keywords for it. Marketing teams from publishers did end up getting word of it and used it regularly.

The backend again used Akka actors (Scala), with each remote actor pulling book data and reviews live in parallel to aggregate and run a pipeline of inference models to generate and rank the keywords.
This keyword product I ended up selling to a number of publishing companies, including Ingram, who still use it today at scale to generate keywords for hundreds of thousands of books as part of their Marketing Insights product.
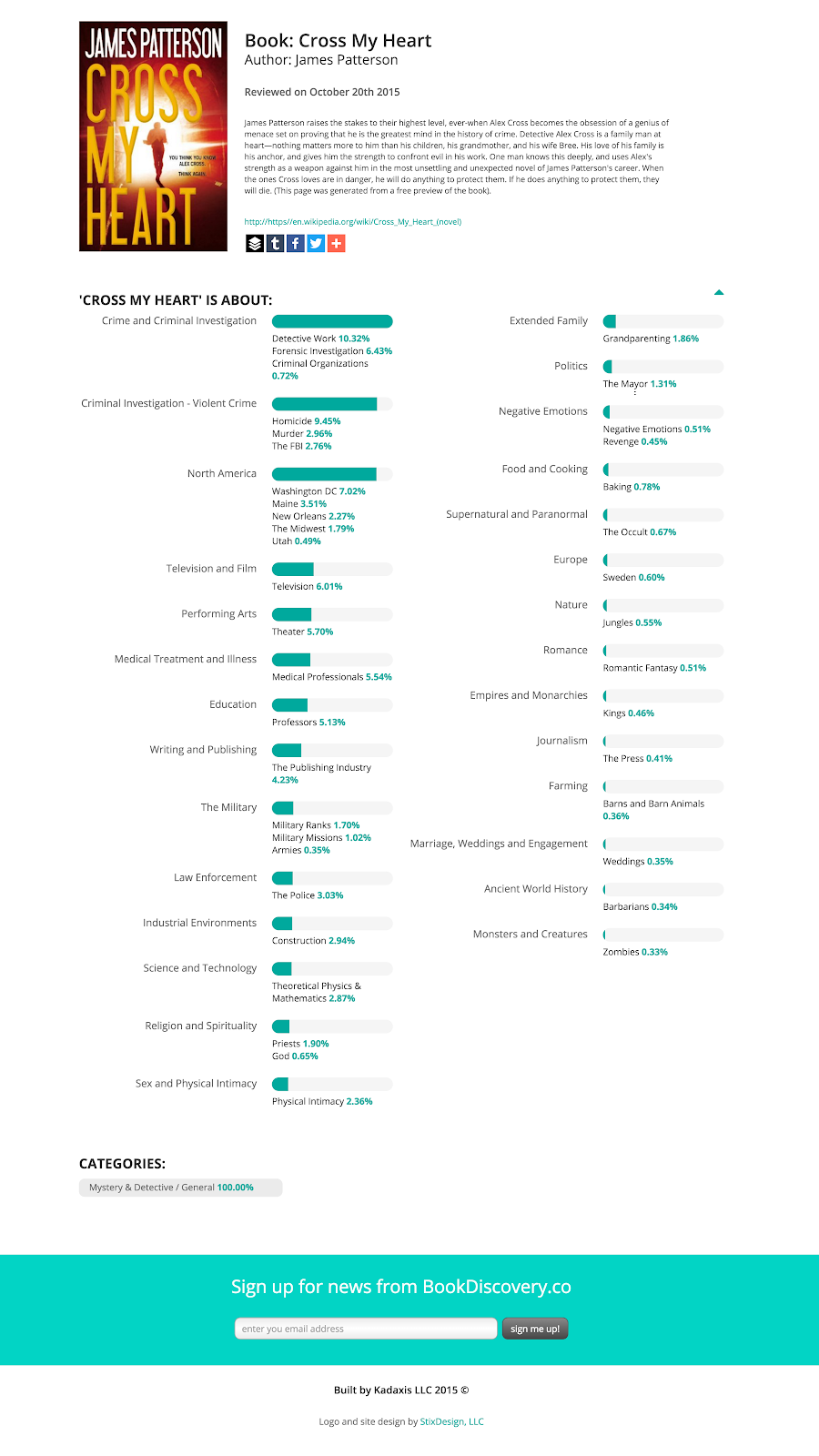
Along with the keyword tool, I also allowed authors to upload their manuscripts for analysis, applying my LDA topic model and BISAC classifiers from earlier, along with analysis of writing style comparing to books that had sold well. (The example below was generated from a preview version of the novel – roughly 10% of the full text)
Book Discovery
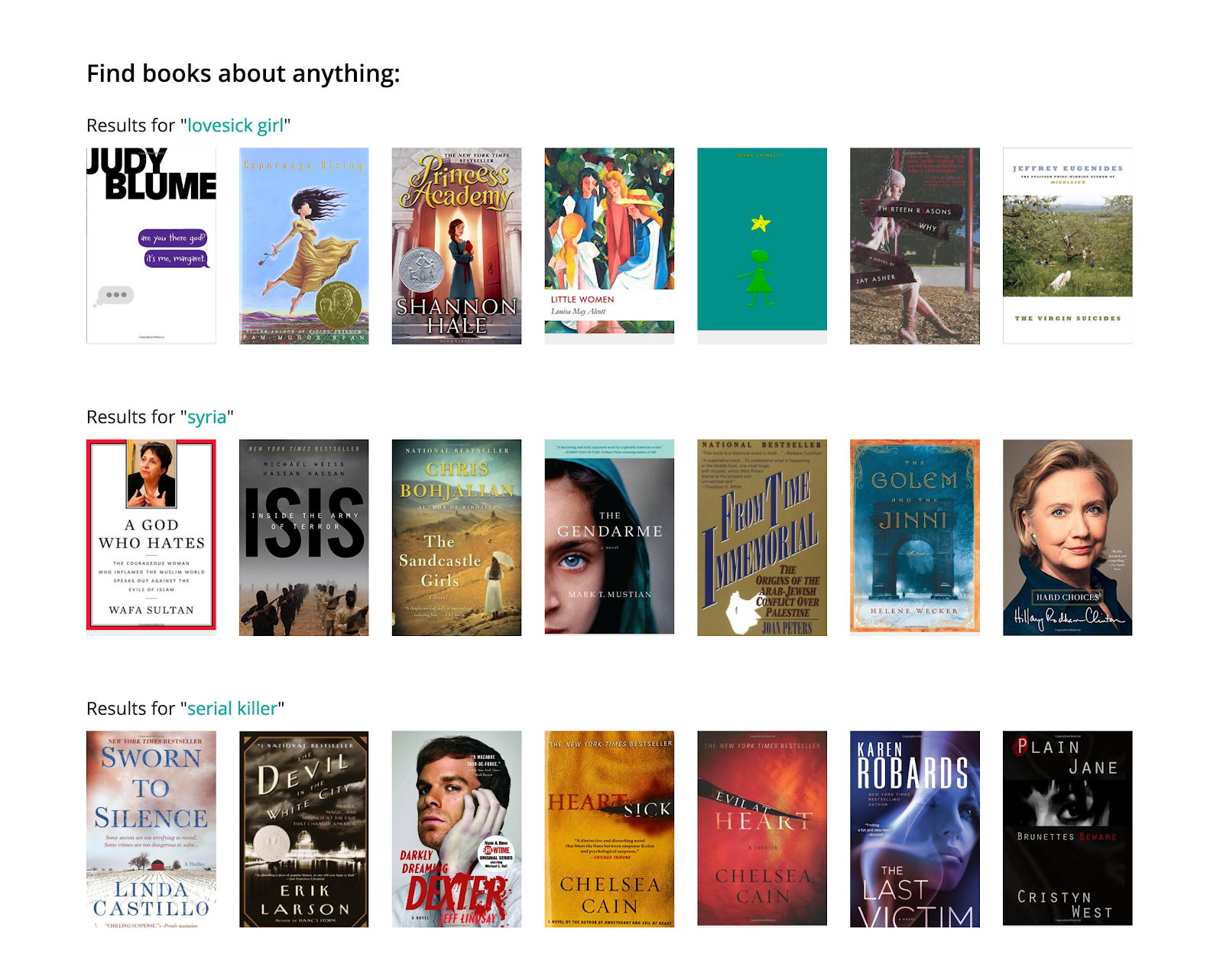
This site was for readers giving them the ability to search for books based on reader experience (vs. book metadata supplied by a publisher).
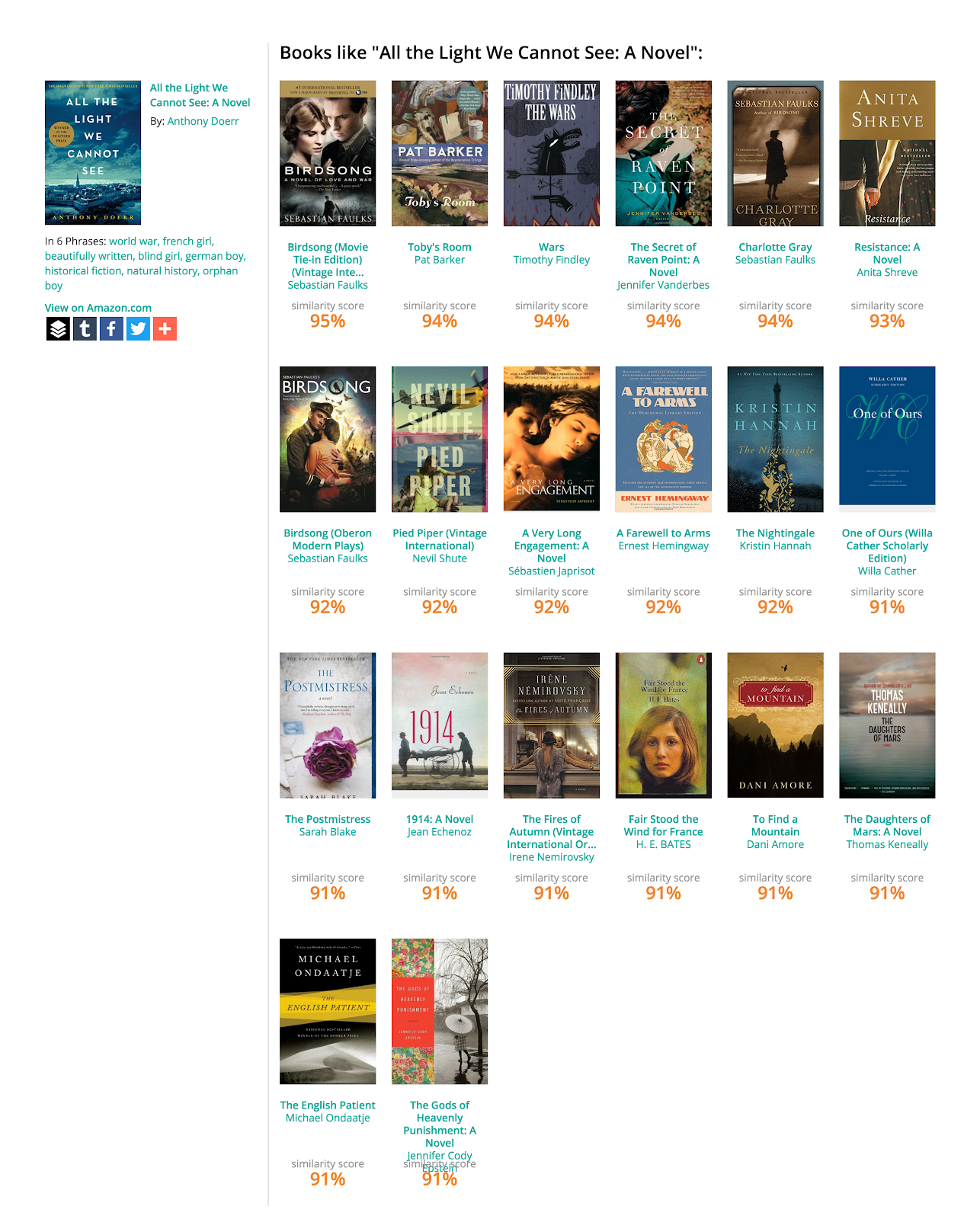
I created various models from the tens of millions of book reviews I had. One feature was book to book similarity created from an LDA topic model from the reviews of each book, then a simple cosine-similarity against other books.
Finding Comparable Titles (Using Reader Reviews):
The site also supported searching by experiences and other criteria other readers identified about books, again beyond the data a publisher might provide.
Finding Product Market Fit With Publishers
After experimenting with the consumer market, I pivoted back to a B2B model selling “audience driven keywords” to publishing houses and built out a richer keyword product – targeted at front list, high value titles (with commercial success).
I took all of my learnings to date and combined a number of models to generate detailed audience and keyword reports and associated key phrases for publisher marketing teams. I won’t detail all the models involved, but the platform generates keywords (vs. matching from a keyword database). The (current) model pipeline includes multiple NLP / machine learning models, incorporates GloVe word vectors and GPT-3 for a filter classifier trained off a dataset from our analyst’s manual keyword filtering).
The breakout moment occurred after running a study in partnership with Firebrand (a book metadata company). We took books from a number of their publisher clients, added Kadaxis AI generated keywords and measured sales. The full study is available here. Many publishers saw significant sales improvement after adding keywords.
From that point, I was able to sell to many publishers, including most of the big four. I spoke at conferences, picked up awards, including winning FutureBook BookTech Company of the year and making the BISG Industry innovation award shortlist.
Further Experiments in Search and Book Discovery
Beyond the flagship keywords product that I sold to publishers, I experimented in many other areas, including:
Facebook Audience Targeting for Publishers
- Most ad campaigns shape audiences based on intuition or historical context.
- Our approach was to uncover audience insights from book reviews to better target audiences for ad campaigns.
- Partnered with Dr. Juola whose stylometry research uncovered J.K. Rowling as the author of A Cuckoo’s Calling
- Pitched to a big four publisher in London
Search Rank Prediction For Book Catalogs
- Used to identify which books within a catalog would benefit most from adding keywords.
- Provides publishers with large catalogs (thousands to tens of thousands of books) with the ability to surface high opportunity books for keyword marketing.
- Model was created by testing the search rank of thousands of books from many tens of thousands of search queries on Amazon.
- BISG webinar discussing how these on-page features can be used to assess keyword efficacy for a book
Amazon Product Advertising Keywords
- Expanded application of audience keyword technology, incorporating rules for Amazon Ad campaigns.
- Competitive analysis of books for sale on Amazon used as audience source data.
- Generate 1000 keywords for use in targeted ad campaigns.
There’s one final chapter to write in this story, coming soon.